
...
Jan suggested to work with two dimensions in the classification: problems and causes. I immediately knew that was it! But how does that work, a classification with more than one dimension? I started to study the theory of classification, and I realized I had always been restricting myself to a certain form of classification, namely a taxonomy.
In a taxonomy, an object can occupy only one place in a hierarchical system: classifying a dog in a taxonomy of animals means positioning it at one of the branches of a tree, by means of characterizing it according to certain variables which are considered in sequence.
However, there is also a more complex form of classification: a typology. An example of a typology would be the characterization of a group of people according to their gender as well as to the colour of their hair. Each individual is not positioned within a hierarchical structure, as in a taxonomy, but characterised according to two variables that are considered in parallel, instead of in sequence.We needed a typology! The argumentation for each conjecture necessarily has two dimensions, the detection of a problem (in the transmitted text) and the suggestion of a cause of the supposed corruption (that is, a certain type of scribal error/change). ..."
Kamphuis' discovery parallels several other problems in both the organization of data and the display of data in NT studies.
Consider first of all the problem of grouping manuscripts. Lately, researchers have been trying two, three and even multidimensional systems for graphing and measuring the 'closeness' of one manuscript's text to another, looking for 'clusters' or groups that have some substantial objective measure.
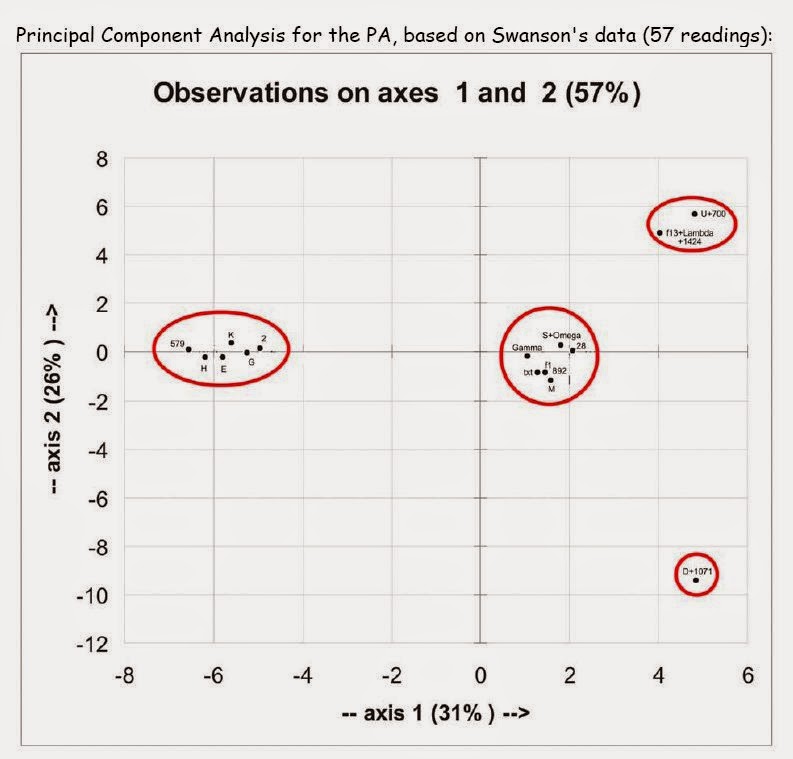 |
Example: Willker's Principal Components Analysis |
Secondly, we often want to display relationships that are in fact quite complex, but best comprehended in 3-dimensional or 2-dimensional charts, which often must either leave out 'dimensions' of a problem or else distort them.
Consider for instance, a Synoptic relationship diagram, such as this:

Already we can see that certain details are left out or simplified (e.g. "other sources").
Or again, our own experience in trying to give an informative chart of the transmission data for a mere 12 verses of gospel (John 8:1-11):

But I'd like to draw attention to the specific fact that almost all "Evolutionary thinking" in the 19th and 20th centuries was based on the "Taxonomy Paradigm", and that, bluntly stated means the 'experts' were committed to a form of "One-Dimensional" sequential thinking, and viewpoints: it was the only 'science' they had available at the time.
Perhaps this fundamental commitment to contemporary "science" as they understood it, forced them to abandon even 'common sense' in regard to the data regarding (accidental) omissions in ancient manuscripts, and embrace the only 'scientific' methodologies available, namely taxonomy-style approachs.
Could this have contributed to the widespread and large-scale 'blindness' regarding the majority of homoioteleuton omissions in the most ancient Uncial manuscripts and texts, and the almost mechanical and irrationally stubborn embrace of the "Prefer the Shorter Reading" axiom?
Kamphuis tells us also of the experience of 20/20 hindsight we all can relate to:
"But again and again some conjecture popped up that posed a problem and called for an adjustment of categories or definitions. Interestingly, most of the time such adjustments made the classification more straightforward, often making me wonder why that didn't occur to me earlier. ..."If early Textual Critics were given another chance at reconstructing the NT text, would they be able to adapt and embrace the more modern and multi-dimensional view of today, and reassess the crude and (in hindsight) misleading 'guidelines' of Textual Criticism of the 19th century?
Would they (unlike their modern ideological successors) recant and embrace the common (traditional 'Majority') Koine text found in the bulk of manuscripts extant today, representing multitudinous lines of transmission?
Would they abandon the "shortest text" in favour of the most likely text?
